Shaobin Zhuang
Focus on video & image generation and unified MLLM.

Shaobin Zhuang
Email: hahahahaha@sjtu.edu.cn
Hi! I am a third-year PhD student of Shanghai Jiao Tong University advised by Prof. Yali Wang. Before that, I received my Bachelor degree from Xiamen University. I also interned at Shanghai AI Lab, Tencent WeChat and Bytedance TikTok.
I have board interest in computer vision, natural language processing and deep learning. Recently, my research mainly focuses on interective video generation and unified generation and understanding model.
I expect to graduate in Summer 2028 and am actively seeking intern opportunities. Feel free to contact me via Email: hahahahaha@sjtu.edu.cn and Wechat:15260330756.
selected publications
-
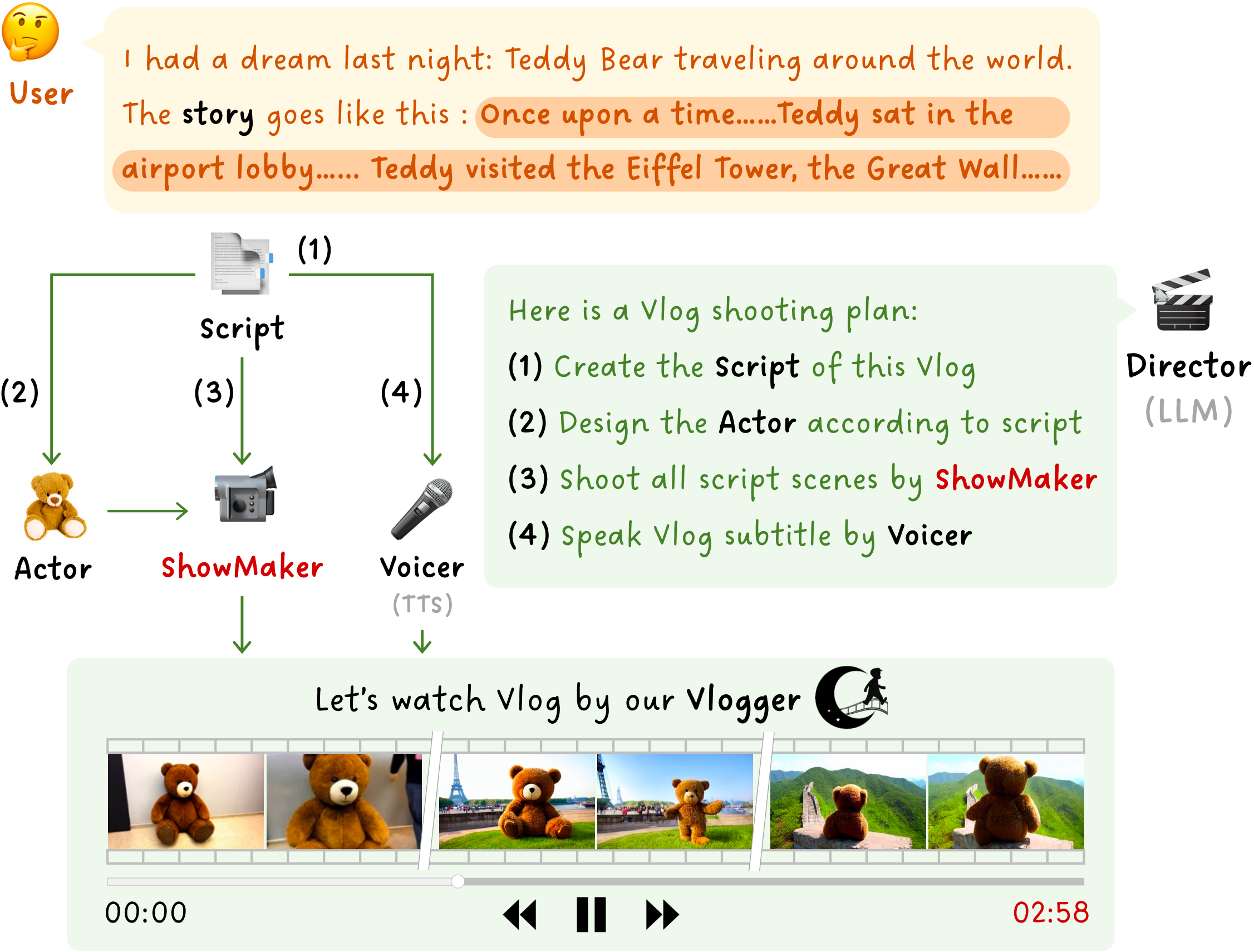
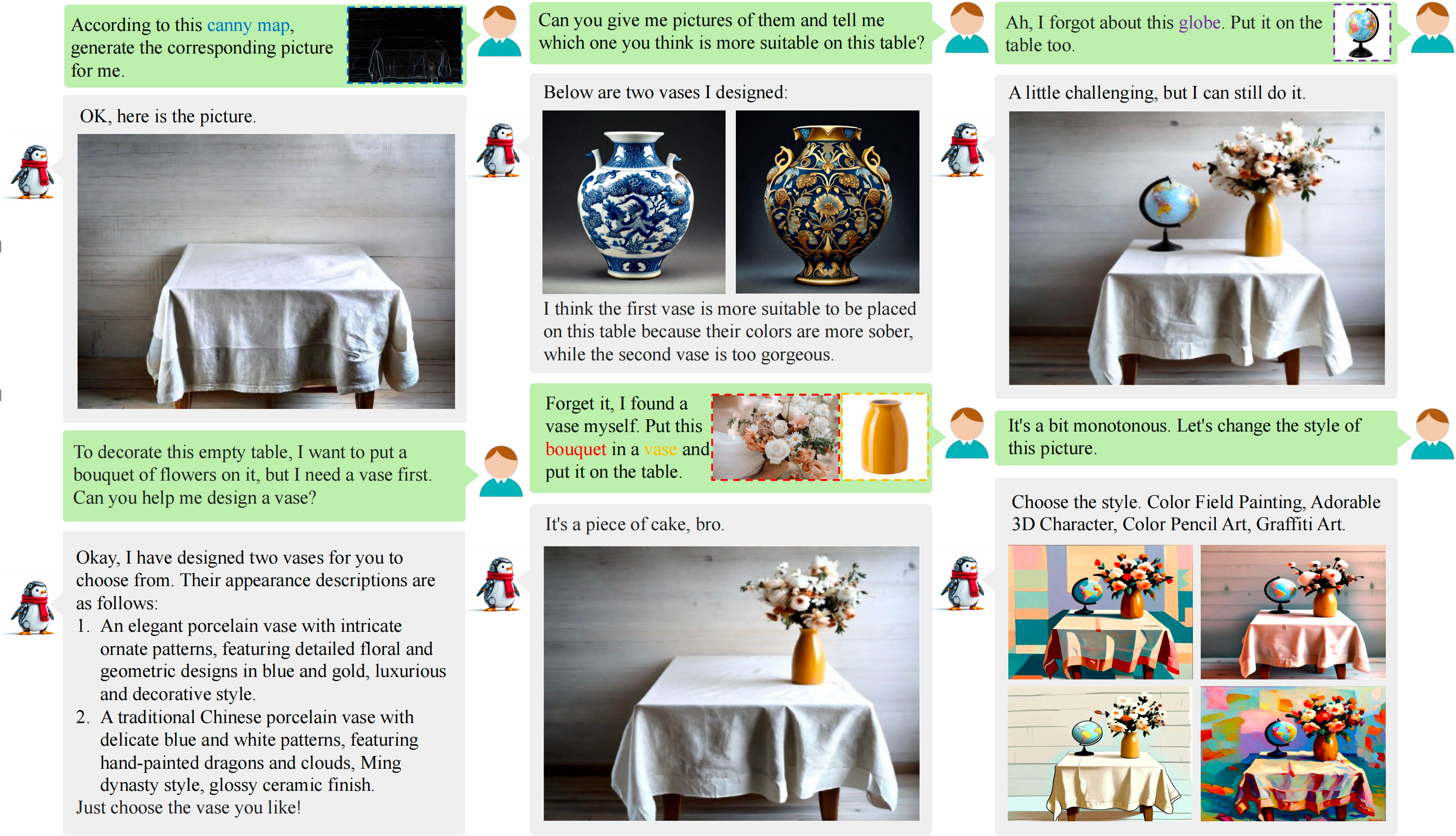
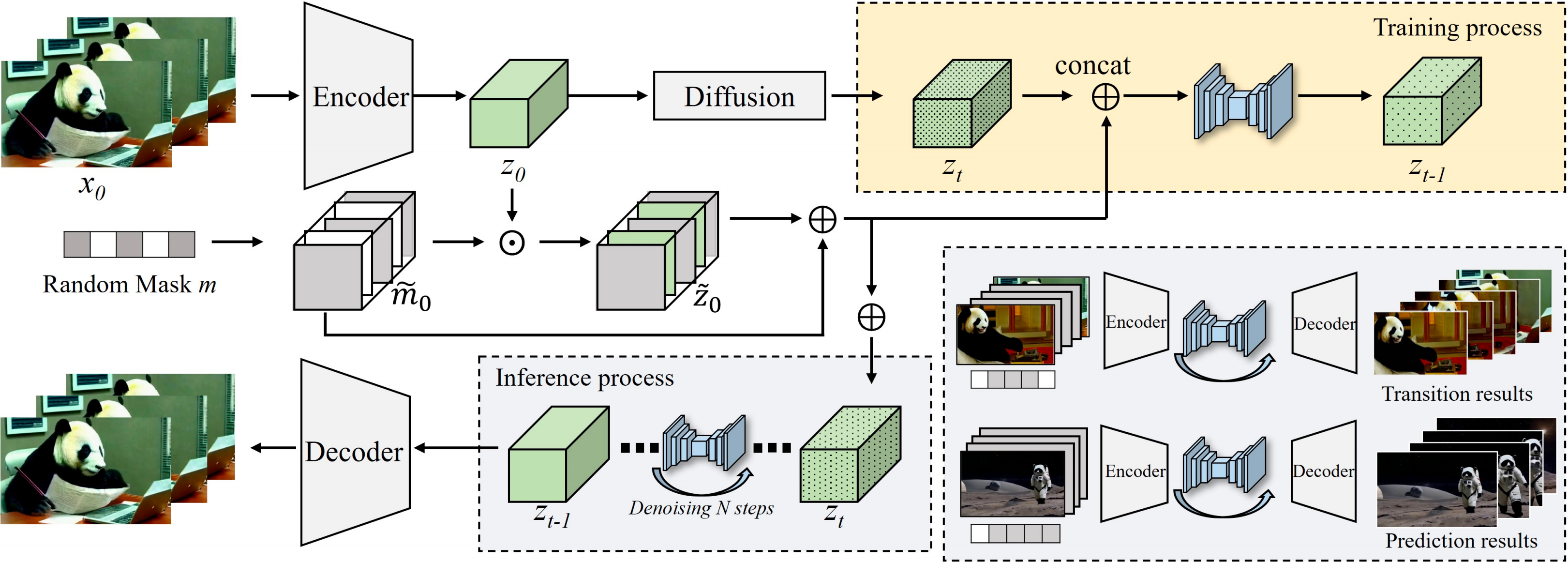
 arXiv preprint arXiv:2602.14178, 2026
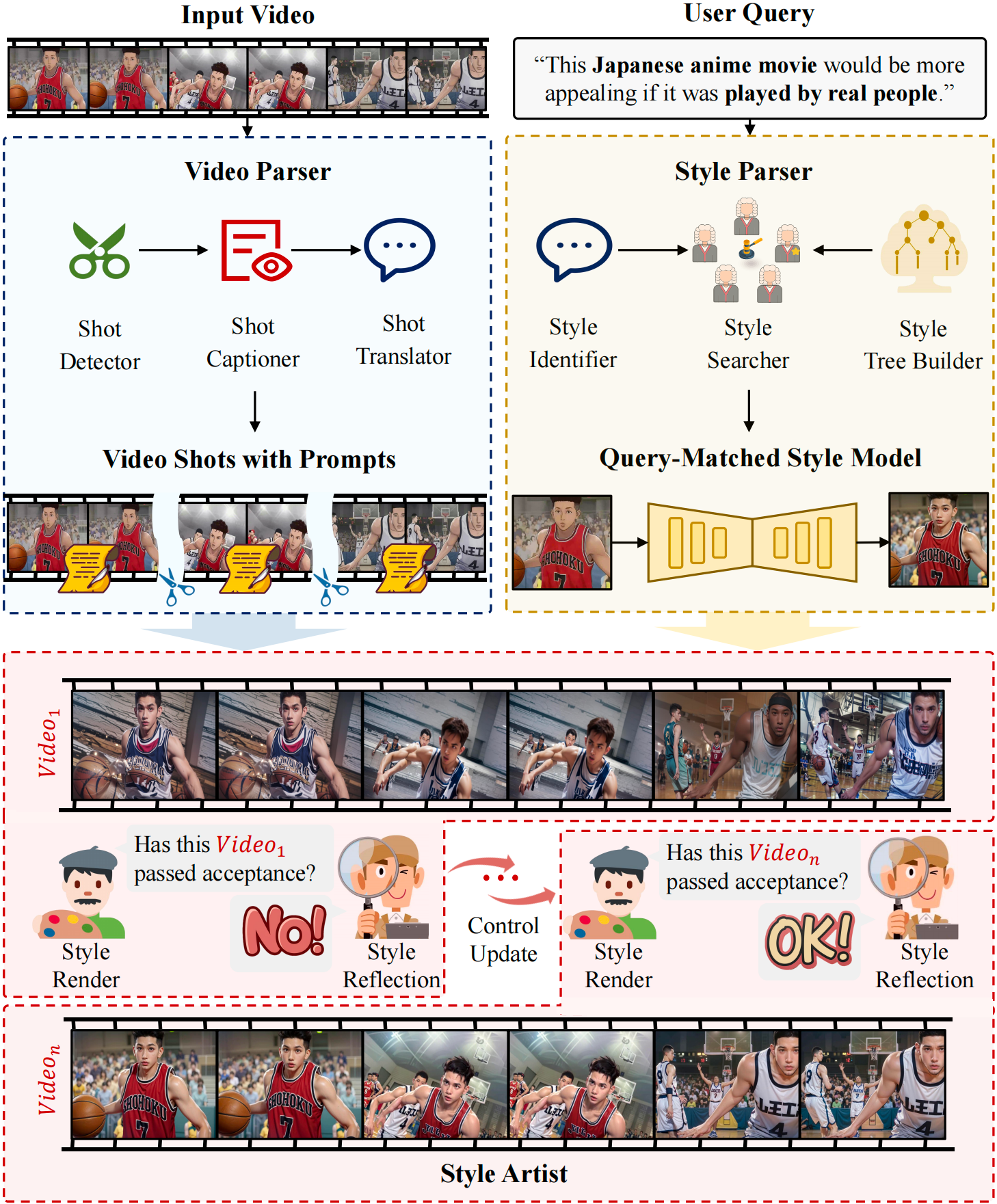
arXiv preprint arXiv:2602.14178, 2026 -
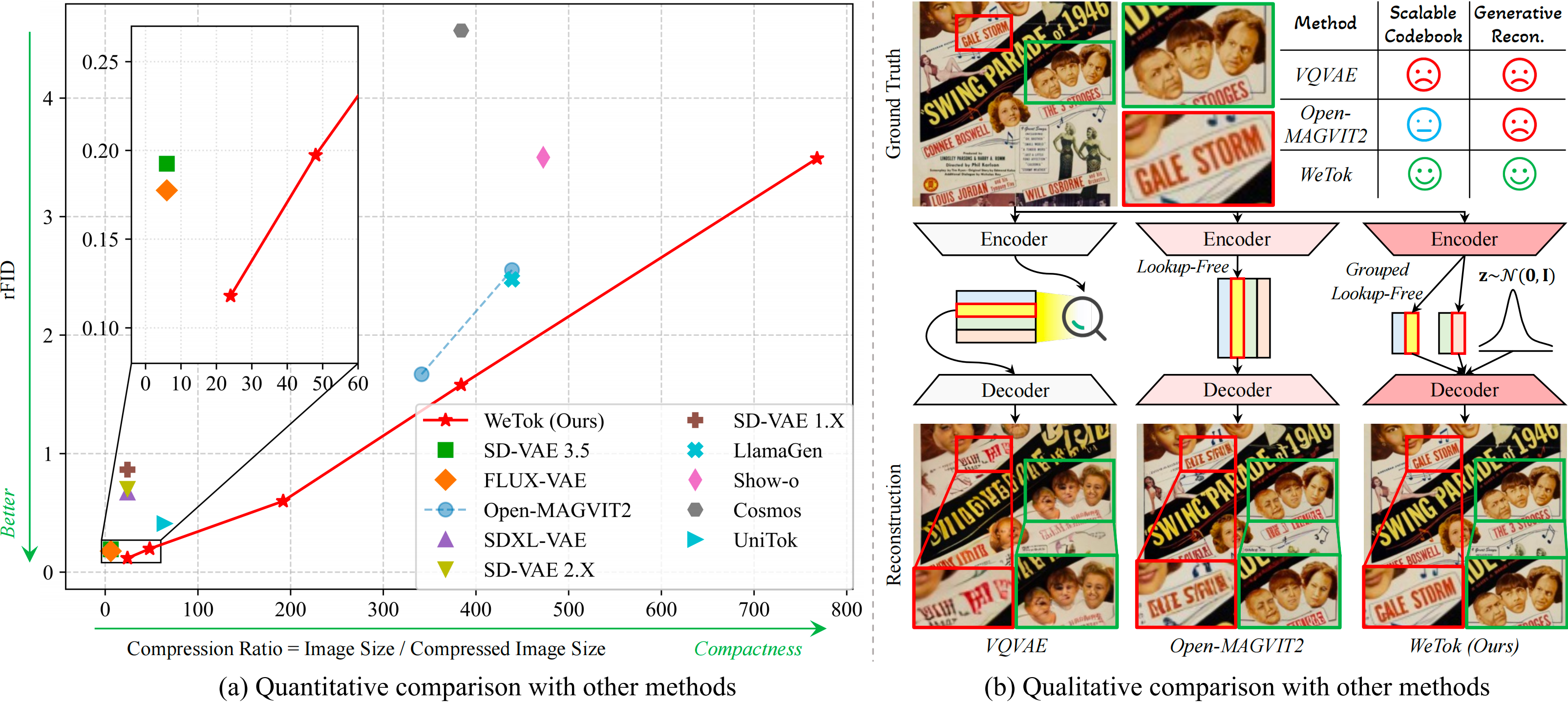
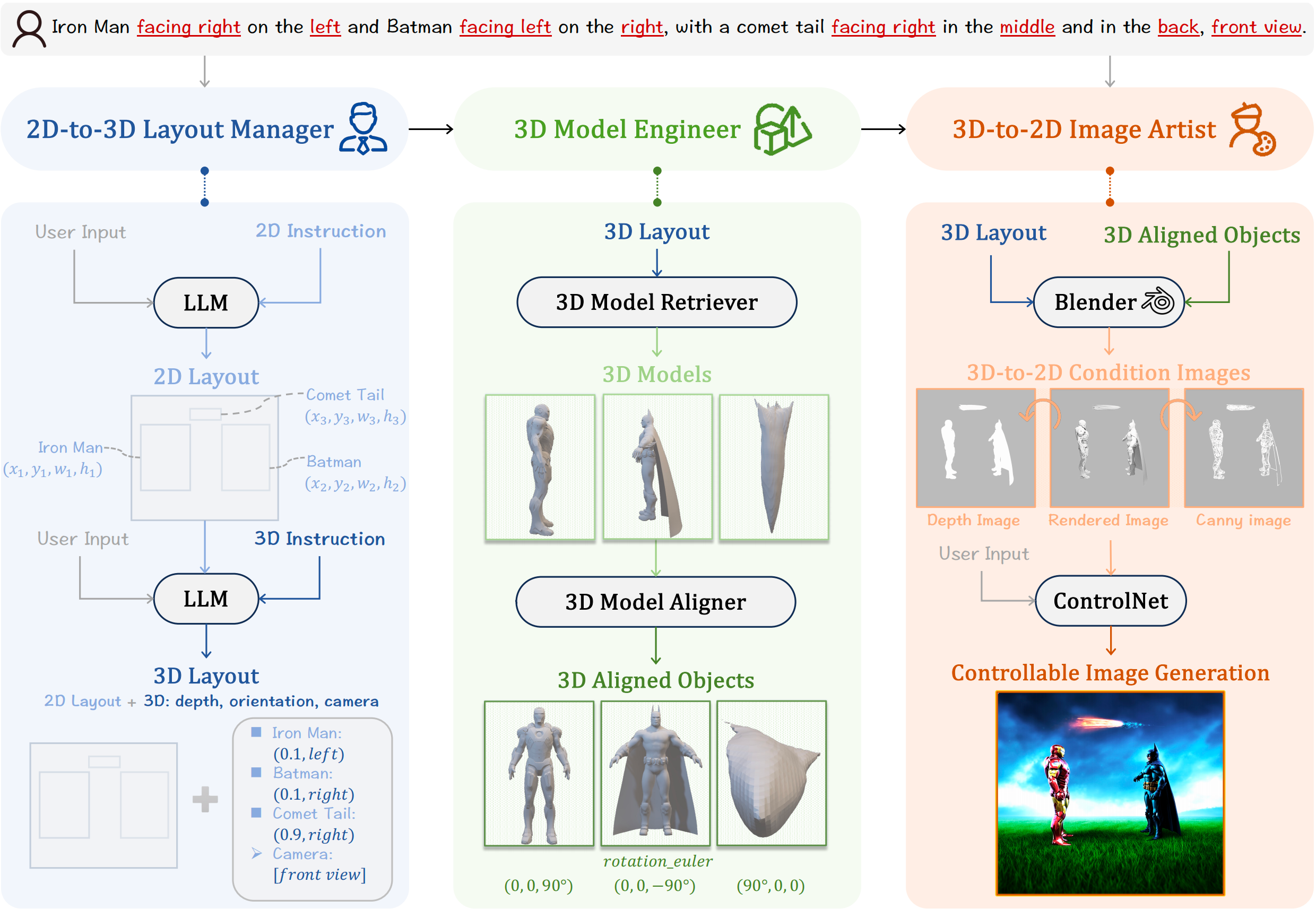
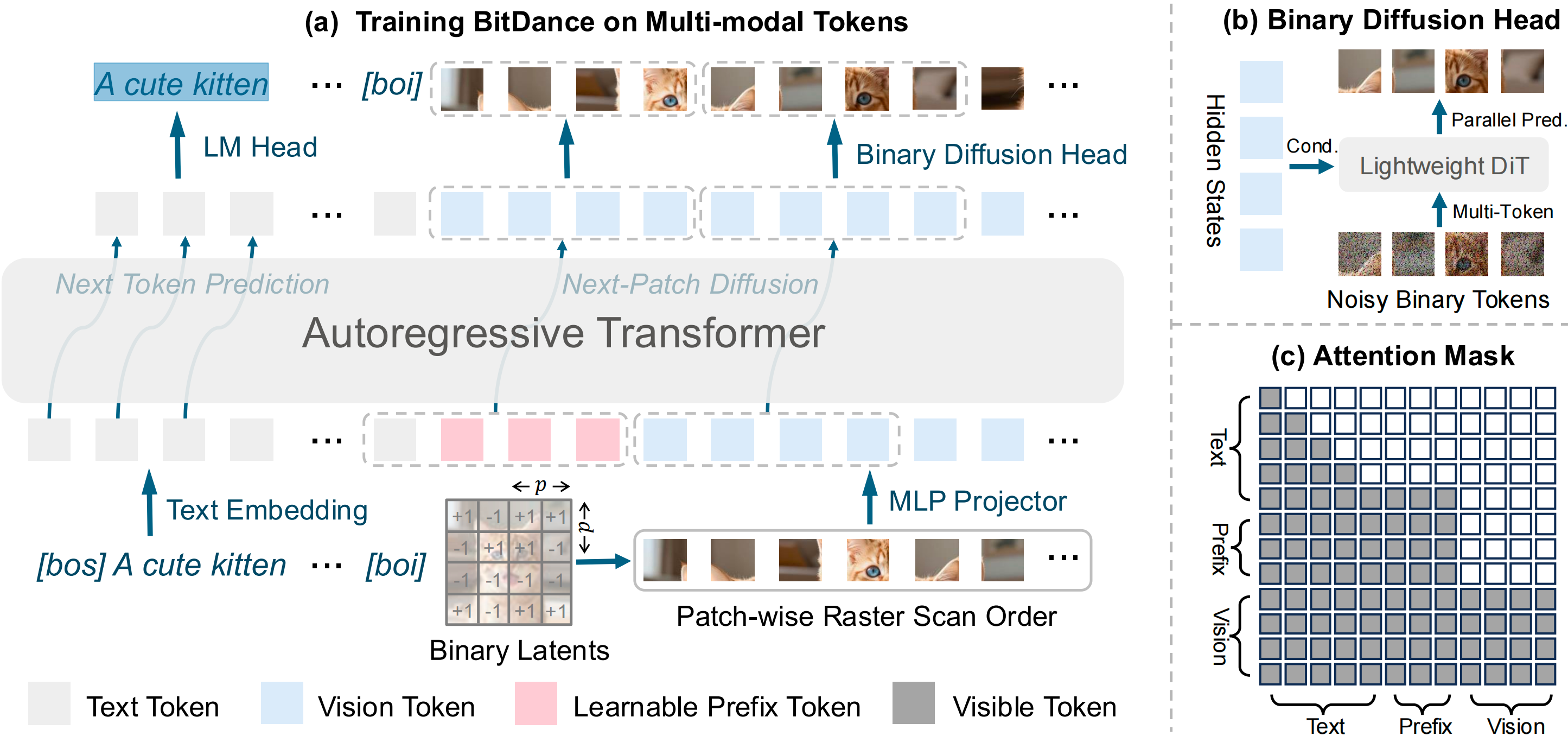 arXiv preprint arXiv:2602.14041, 2026
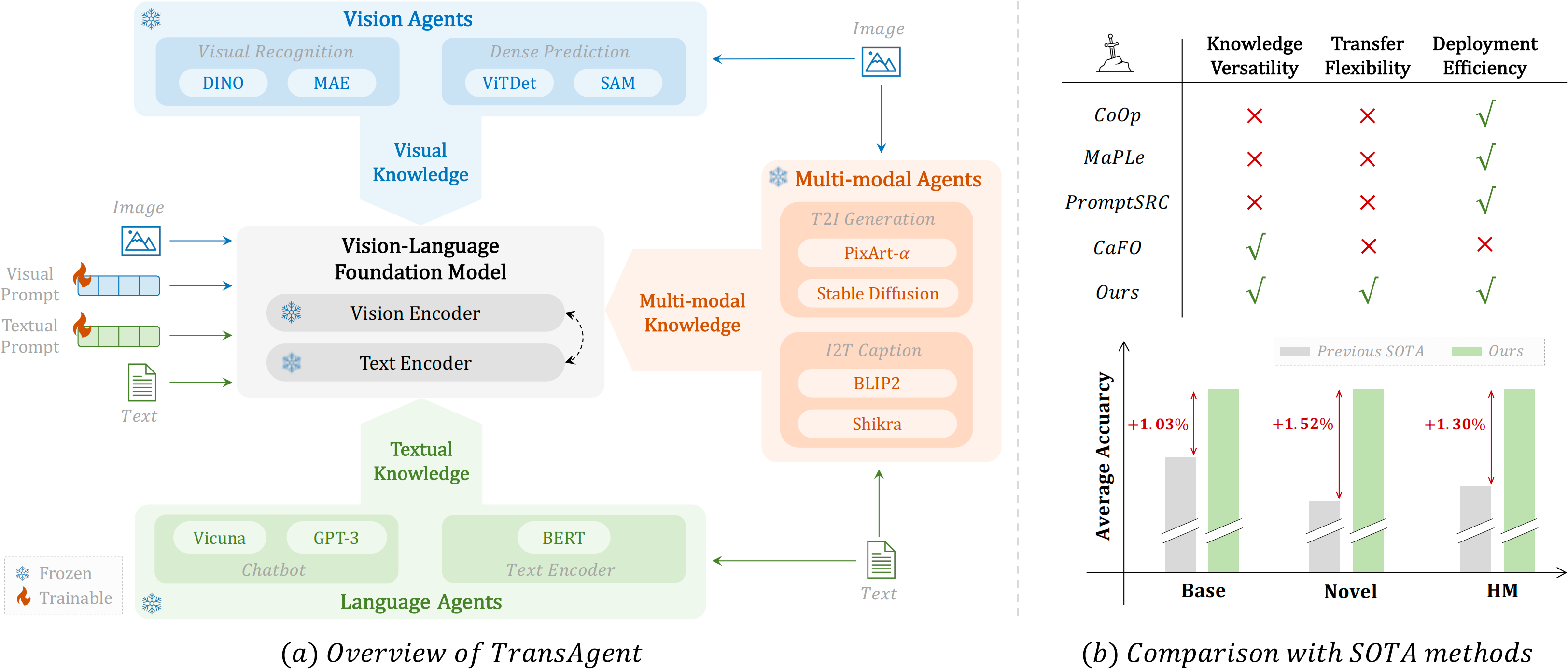
arXiv preprint arXiv:2602.14041, 2026 -
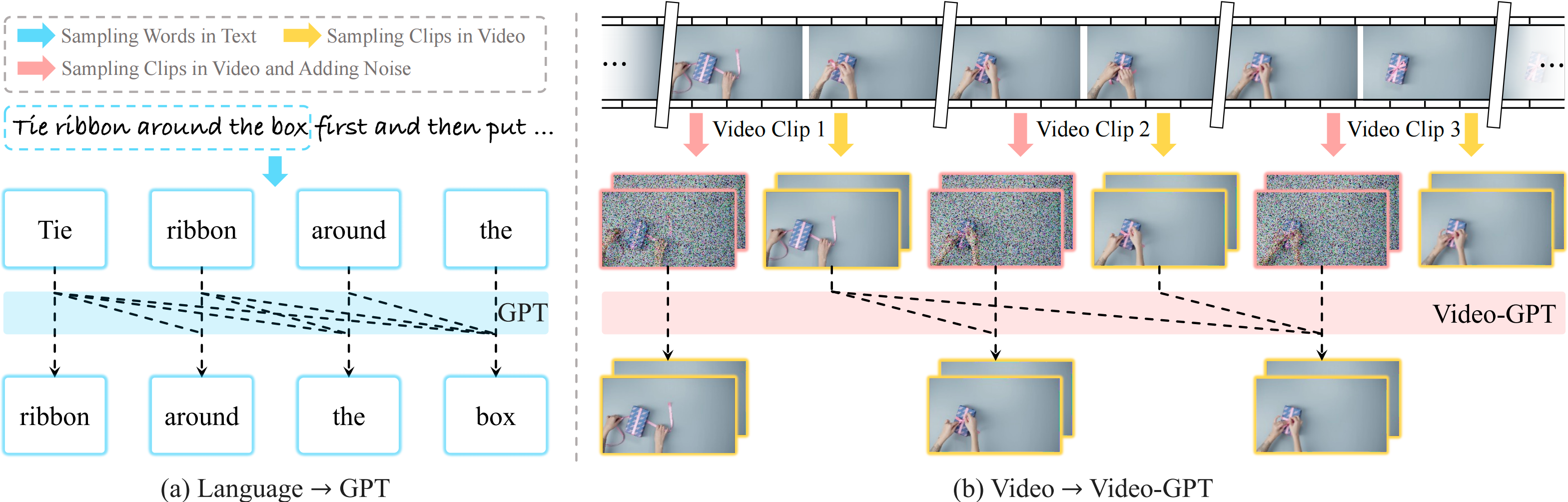
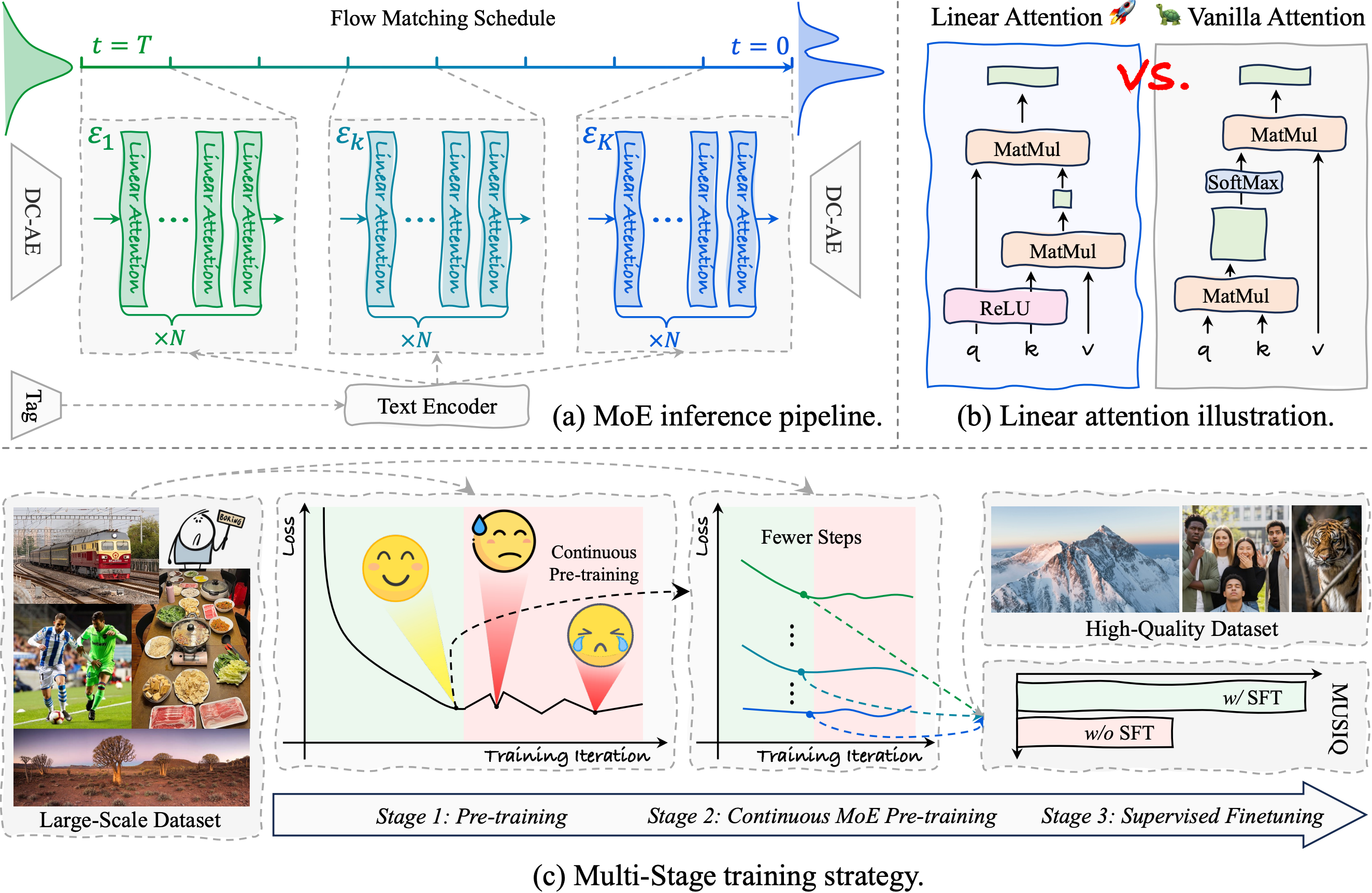
-
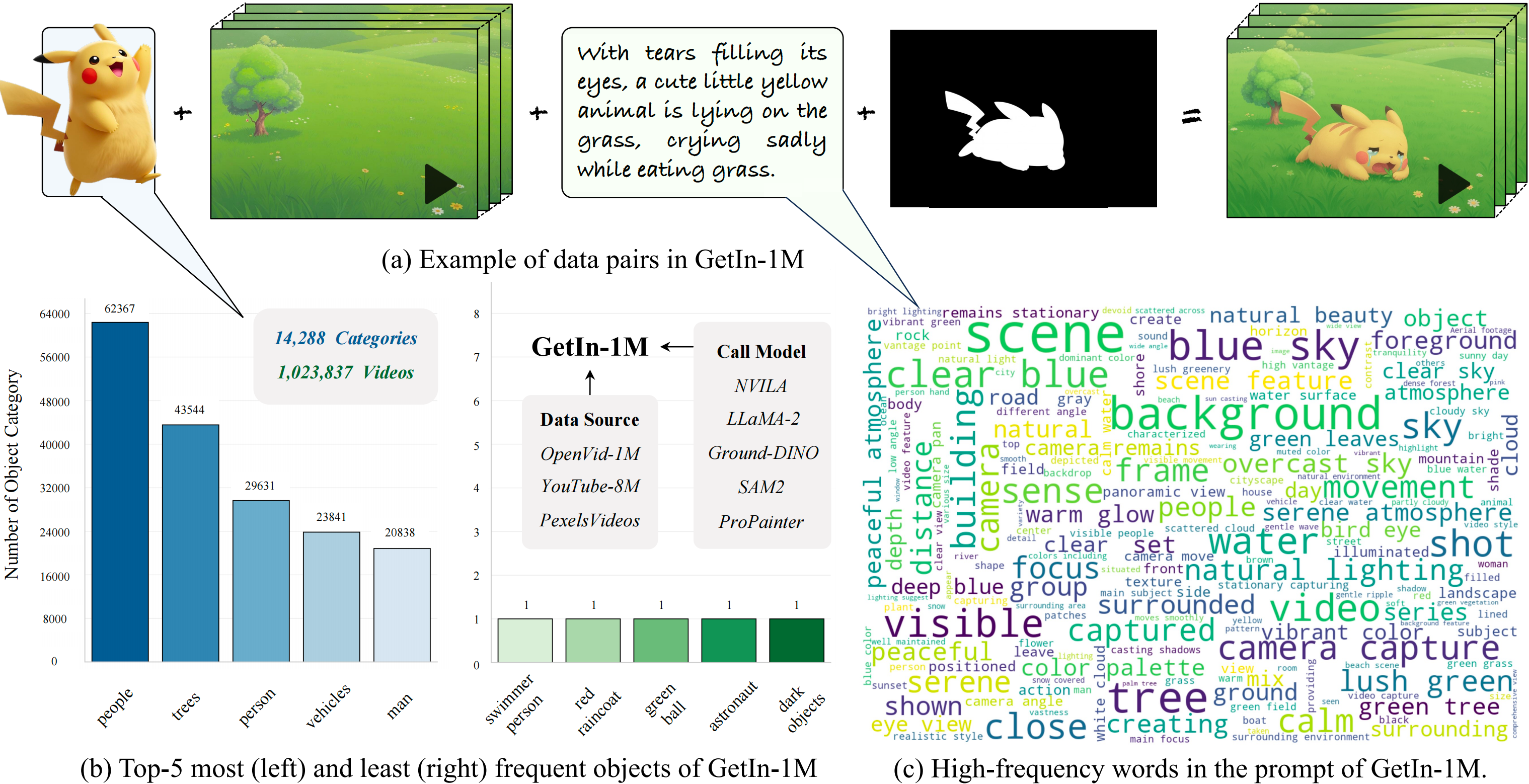
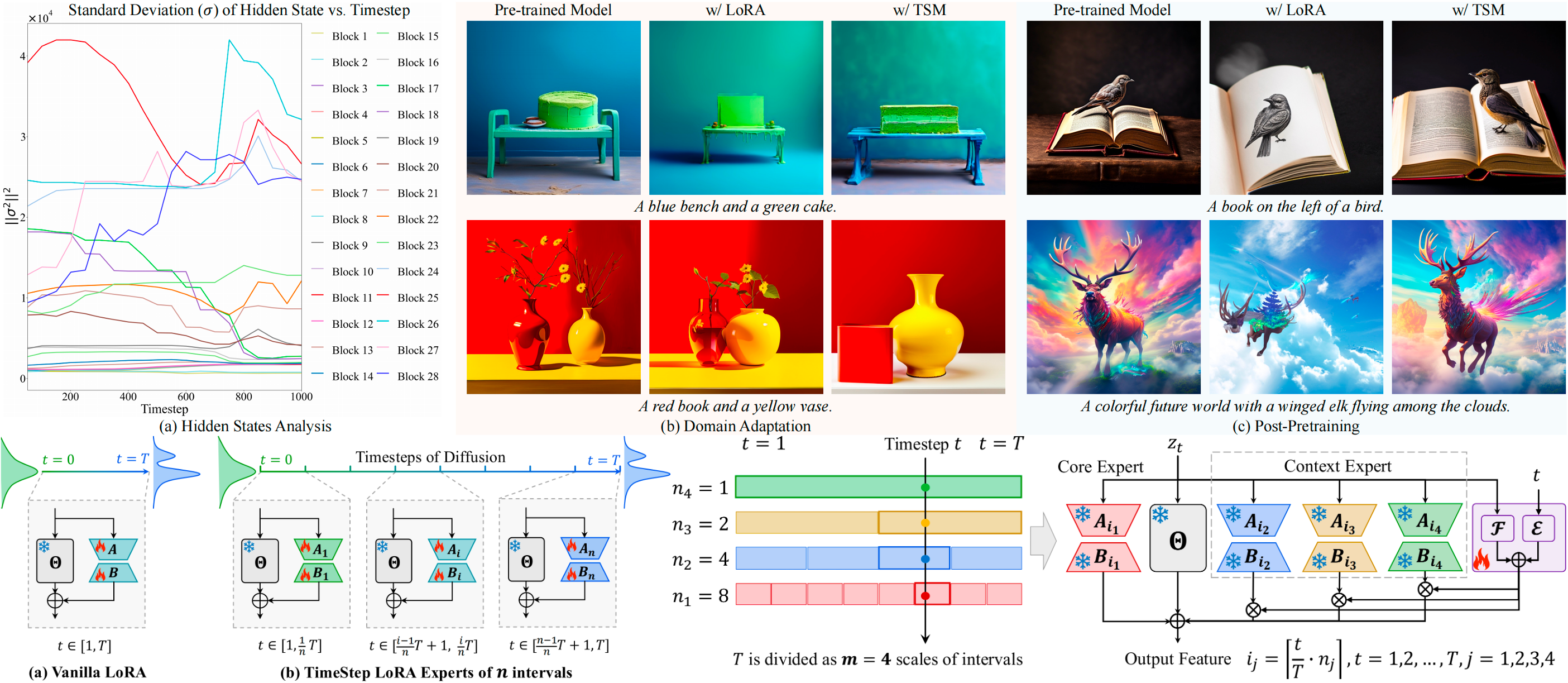
-