publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2026
-
 UniWeTok: An Unified Binary Tokenizer with Codebook Size 2^128 for Unified Multimodal Large Language ModelarXiv preprint arXiv:2602.14178, 2026
UniWeTok: An Unified Binary Tokenizer with Codebook Size 2^128 for Unified Multimodal Large Language ModelarXiv preprint arXiv:2602.14178, 2026 -
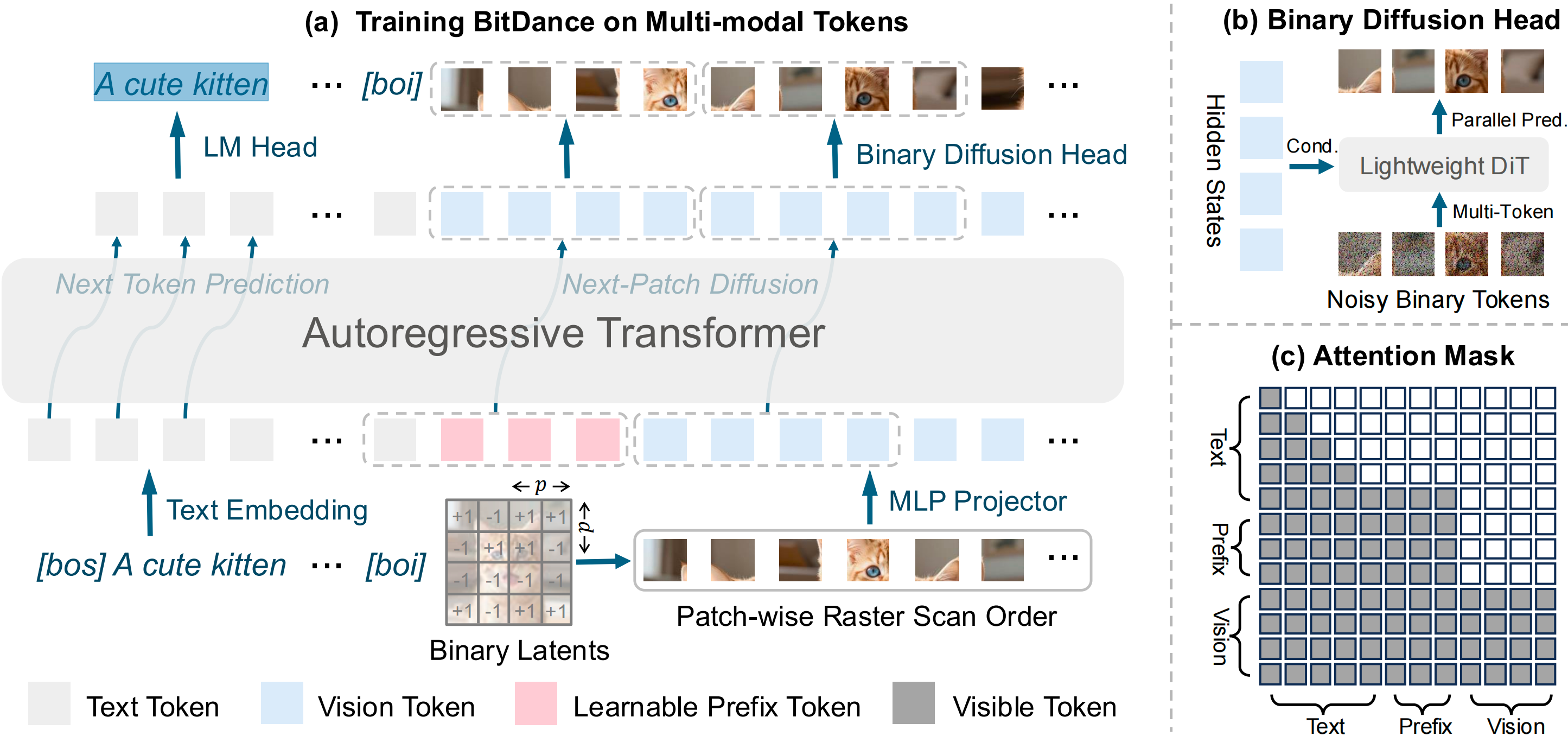 BitDance: Scaling Autoregressive Generative Models with Binary TokensarXiv preprint arXiv:2602.14041, 2026
BitDance: Scaling Autoregressive Generative Models with Binary TokensarXiv preprint arXiv:2602.14041, 2026 -
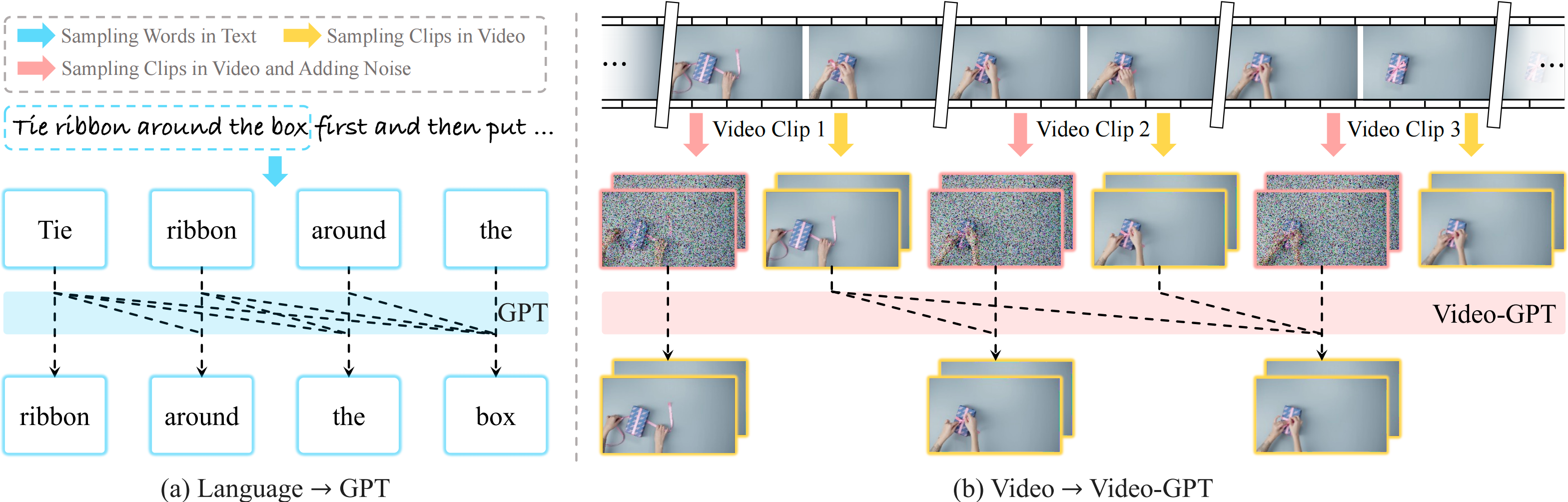 Video-GPT via Next Clip DiffusionICLR, 2026
Video-GPT via Next Clip DiffusionICLR, 2026 -
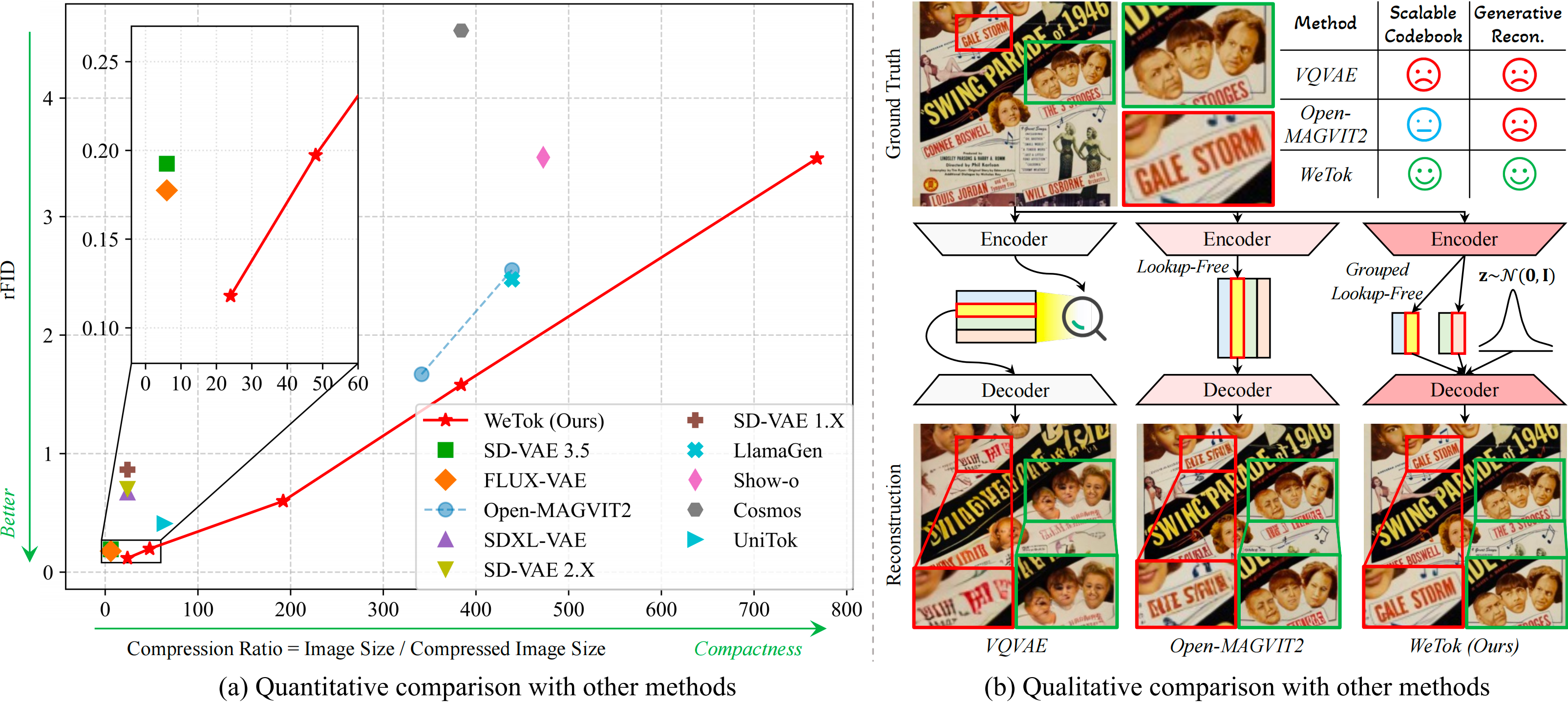 Wetok: Powerful discrete tokenization for high-fidelity visual reconstructionICLR, 2026
Wetok: Powerful discrete tokenization for high-fidelity visual reconstructionICLR, 2026 -
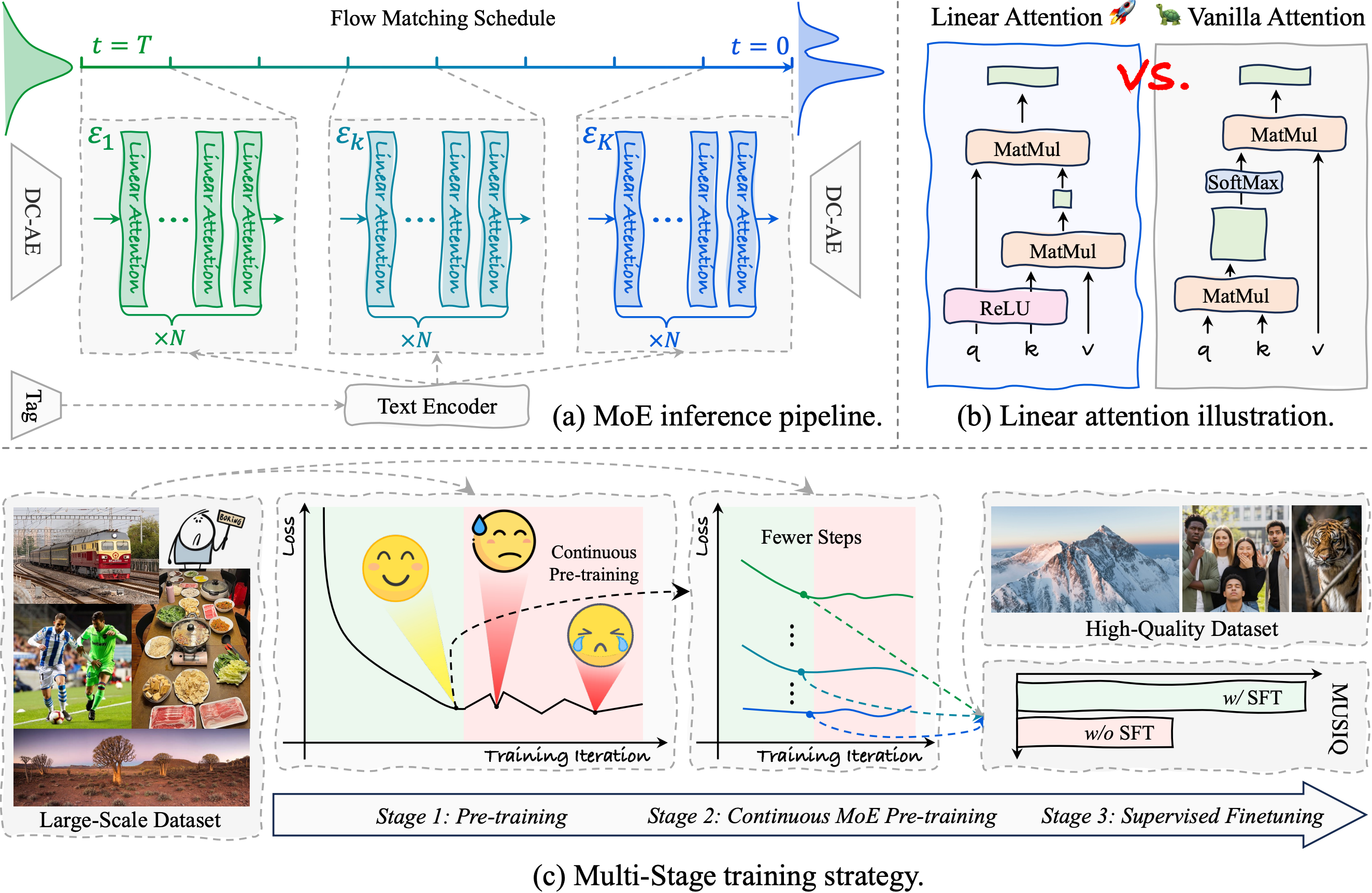 LinearSR: Unlocking Linear Attention for Stable and Efficient Image Super-ResolutionICLR, 2026
LinearSR: Unlocking Linear Attention for Stable and Efficient Image Super-ResolutionICLR, 2026
2025
-
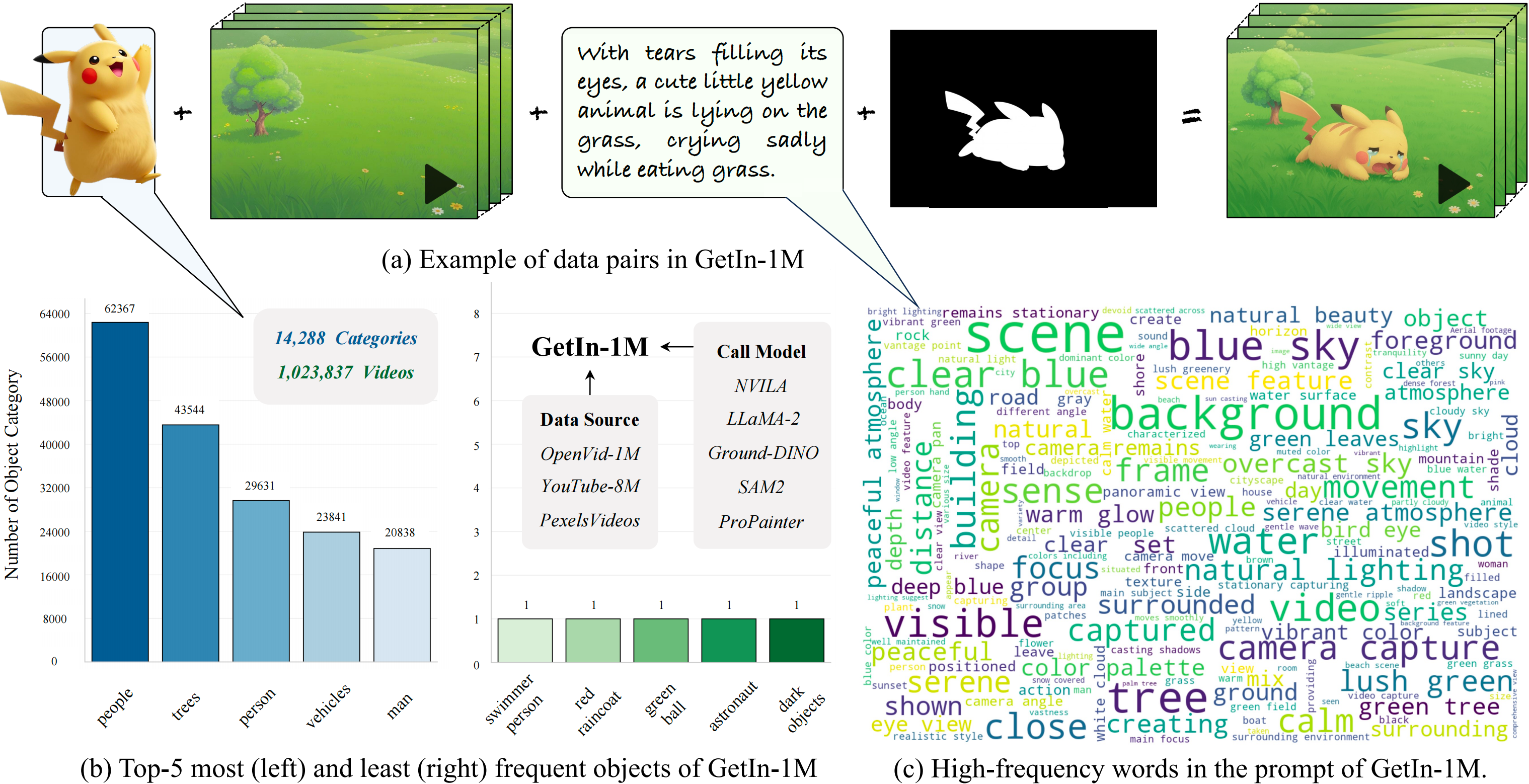 Get in video: Add anything you want to the videoarXiv preprint arXiv:2503.06268, 2025
Get in video: Add anything you want to the videoarXiv preprint arXiv:2503.06268, 2025 -
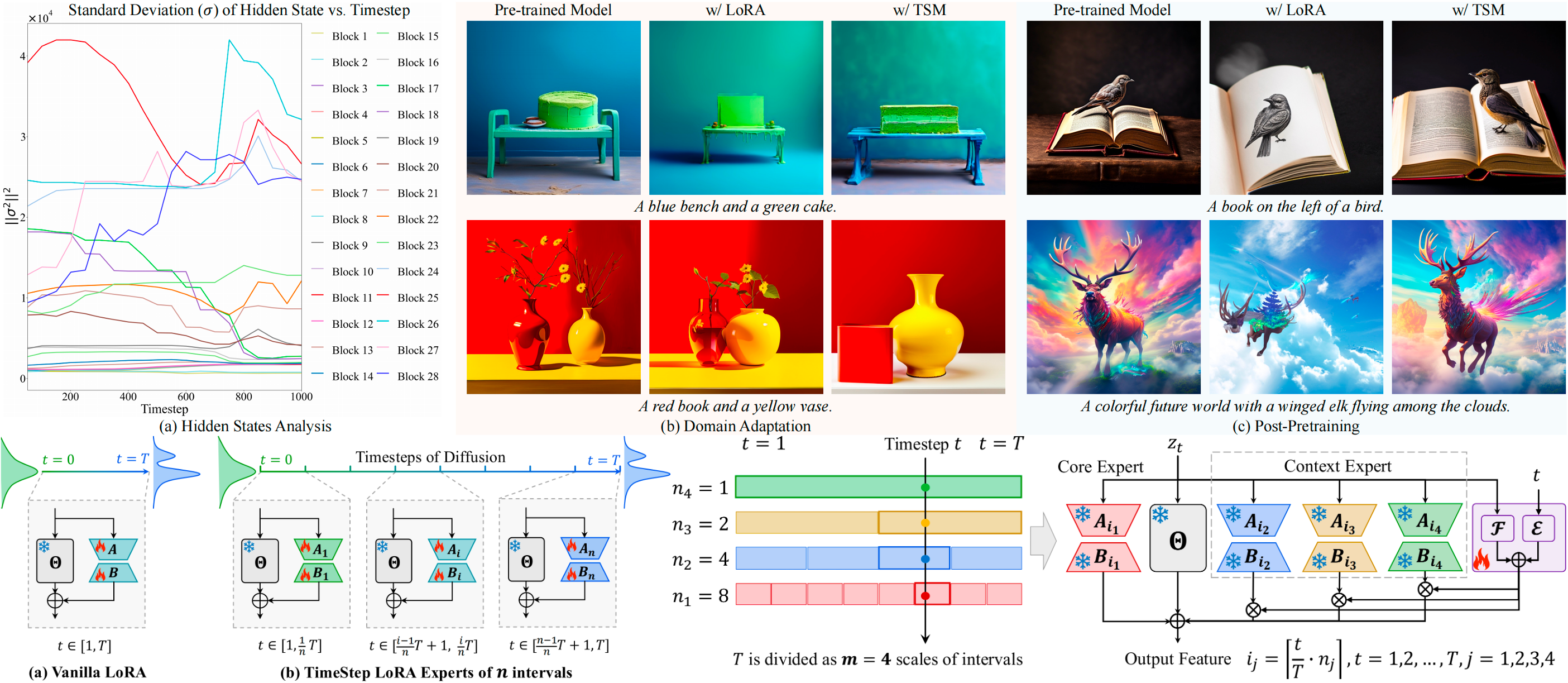 TimeStep Master: Asymmetrical Mixture of Timestep LoRA Experts for Versatile and Efficient Diffusion Models in VisionICML, 2025
TimeStep Master: Asymmetrical Mixture of Timestep LoRA Experts for Versatile and Efficient Diffusion Models in VisionICML, 2025 -
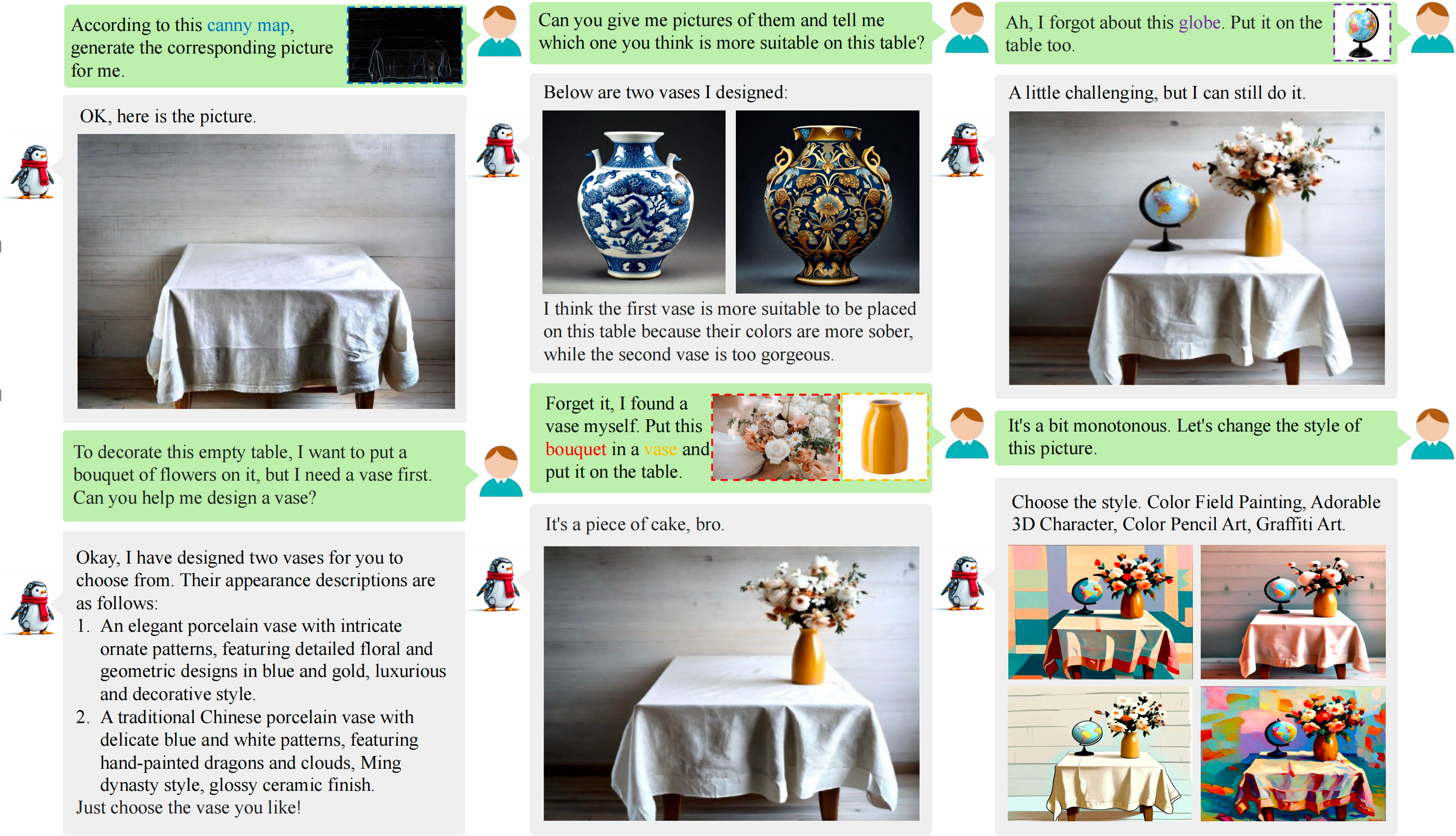 WeGen: A Unified Model for Interactive Multimodal Generation as We ChatCVPR, 2025
WeGen: A Unified Model for Interactive Multimodal Generation as We ChatCVPR, 2025 -
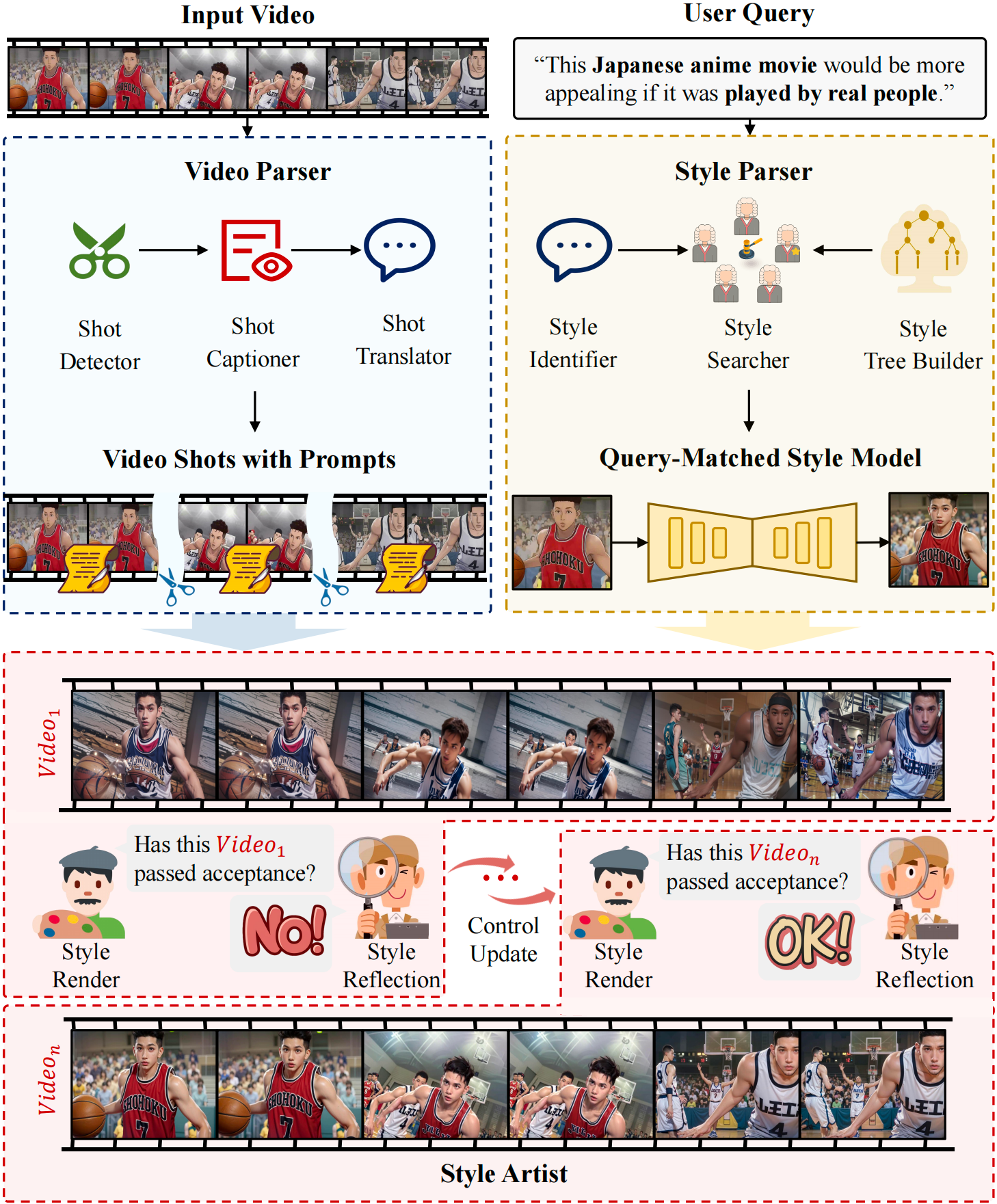 V-Stylist: Video Stylization via Collaboration and Reflection of MLLM AgentsCVPR, 2025
V-Stylist: Video Stylization via Collaboration and Reflection of MLLM AgentsCVPR, 2025
2024
-
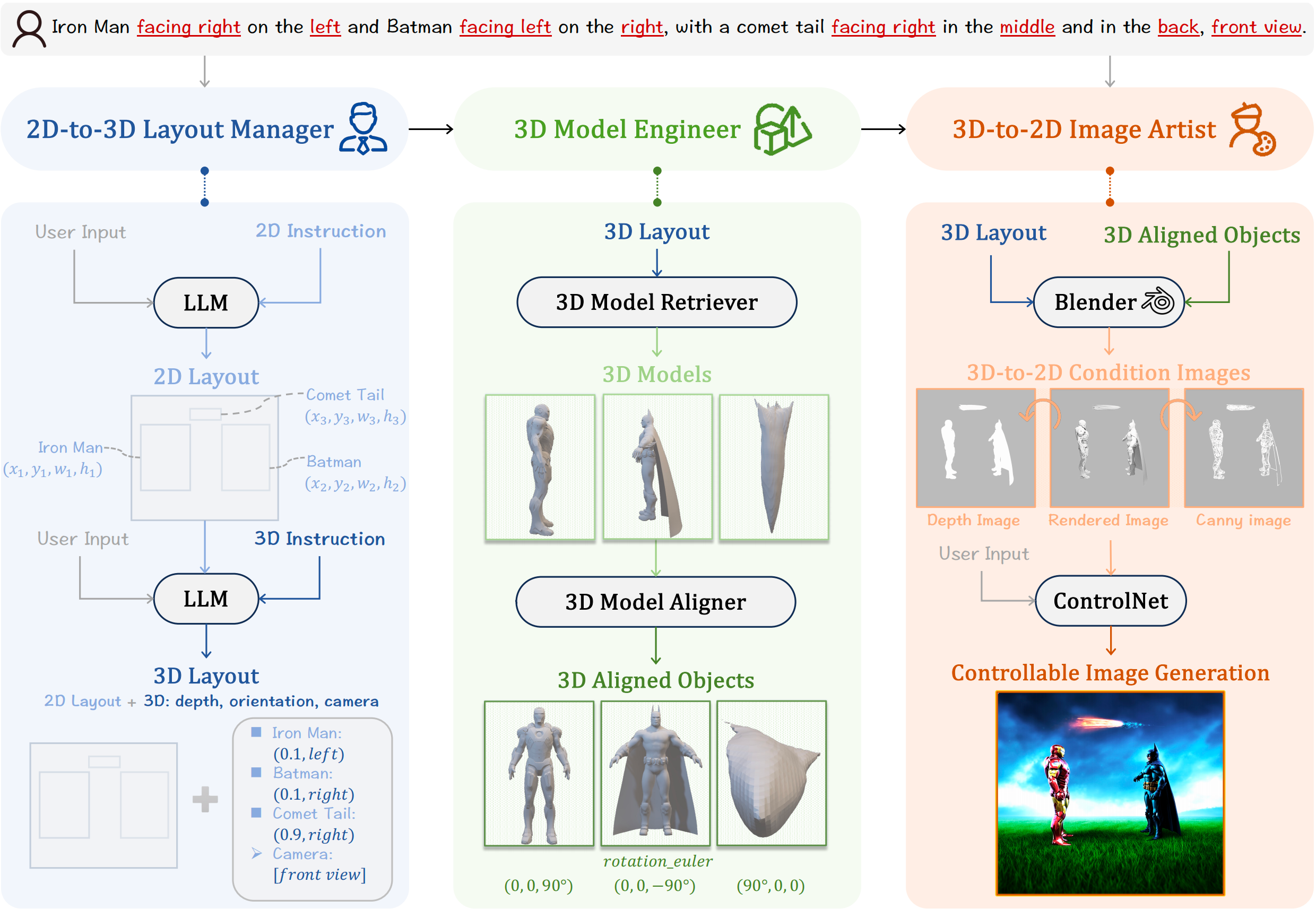 MUSES: 3D-Controllable Image Generation via Multi-Modal Agent CollaborationAAAI, 2024
MUSES: 3D-Controllable Image Generation via Multi-Modal Agent CollaborationAAAI, 2024 -
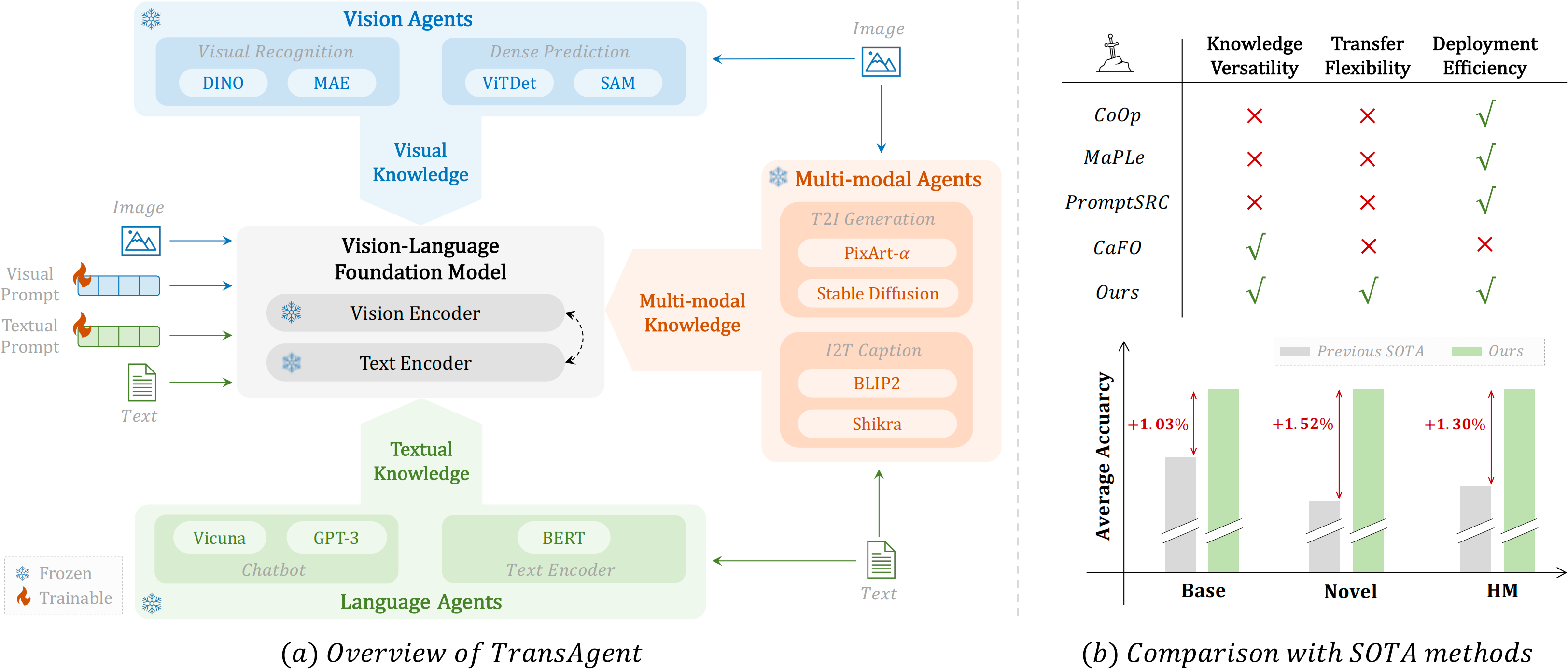 TransAgent: Transfer Vision-Language Foundation Models with Heterogeneous Agent CollaborationNIPS, 2024
TransAgent: Transfer Vision-Language Foundation Models with Heterogeneous Agent CollaborationNIPS, 2024 -
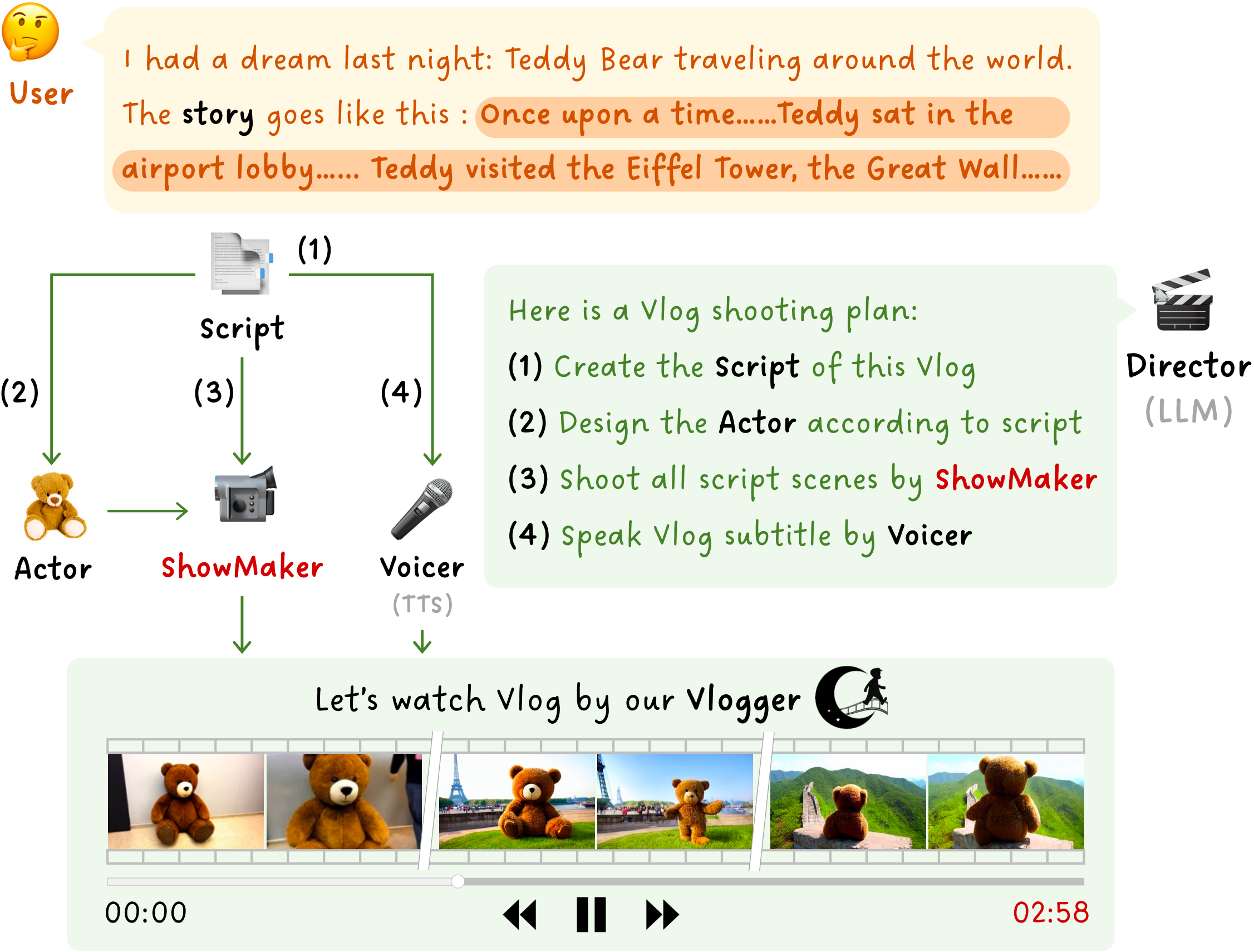 Vlogger: Make Your Dream A VlogCVPR, 2024
Vlogger: Make Your Dream A VlogCVPR, 2024 -
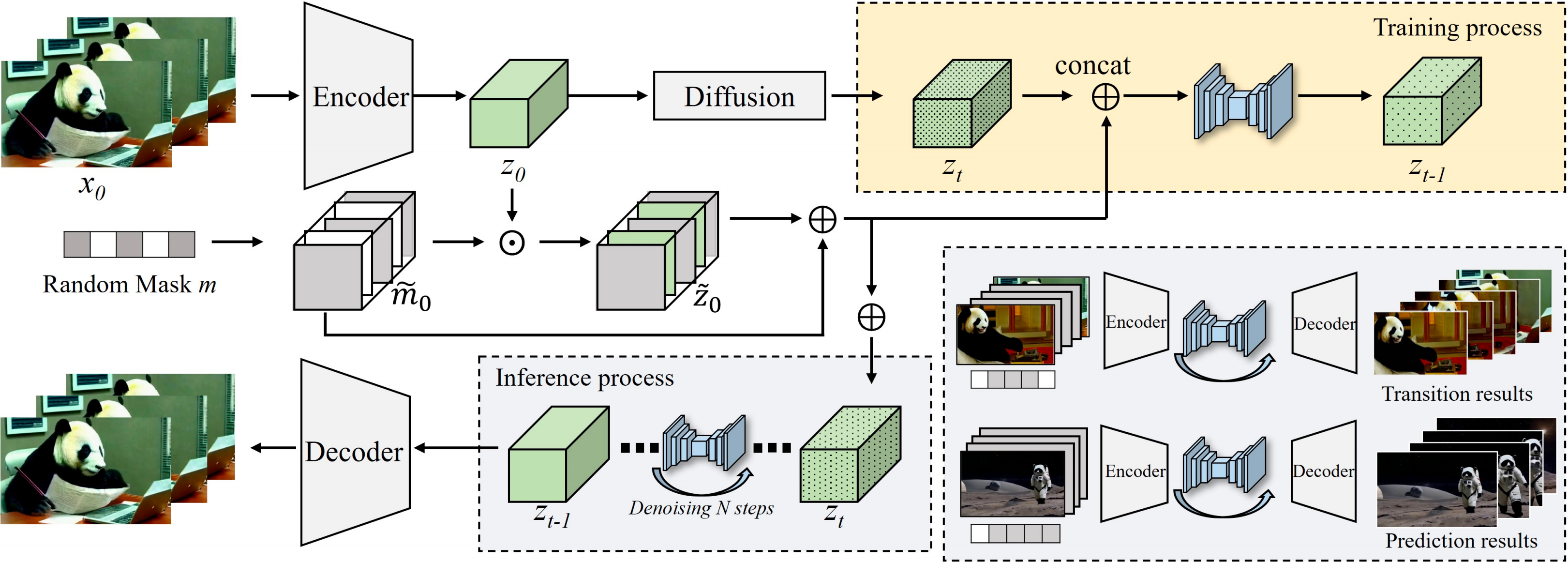 Seine: Short-to-long video diffusion model for generative transition and predictionIn ICLR, 2024
Seine: Short-to-long video diffusion model for generative transition and predictionIn ICLR, 2024